The Scripts Design
Overview
Teaching: 20 min
Exercises: 10 minQuestions
How do the Scripts work?
What is the code structure of the Scripts?
How to improve the Scripts?
Objectives
Learn the organisation and workings of the Scripts.
Learn how the Scripts use the AWS CLI commands.
Learn how to access and use the AWS CLI Command Reference — needed to improve the Scripts.
Prerequisites
This episode has no hands-on activities but you should have covered the two previous episodes, Instances Management Tasks Using the Scripts and AMIs Management, to better understand the concepts presented in this episode.
Overview
Sections
- The Scripts Design.
How the Scripts are organised and how they work internally are the subjects of this section.- The AWS CLI Command Reference.
The Scripts functionality depends on the AWS CLI commands. This section briefly describes the AWS CLI interface and how we used it to develop the Scripts.- Improving the Scripts.
This section describes a few improvements for the Scripts that we may later undertake.
1. The Scripts Design
This section describes the organisation and workings of the Scripts. After you read this section, you will know where to look into the Scripts in case you need to improve them.
Let’s recall the Scripts names:
aws_domainNames_create.sh aws_instances_configure.sh csinstances_create.sh
aws_domainNames_delete.sh aws_instances_launch.sh csinstances_delete.sh
aws_elasticIPs_allocate.sh aws_instances_terminate.sh csinstances_start.sh
aws_elasticIPs_associate2ins.sh aws_loginKeyPair_create.sh csinstances_stop.sh
aws_elasticIPs_deallocate.sh aws_loginKeyPair_delete.sh
aws_elasticIPs_disassociate.sh colour_utils_functions.sh
Organisation into modules
Recall that you run csinstances_create.sh to create one or multiple instances specified in an “instancesNames.txt” file (whose name you can choose), and that each instance is:
— accessed with ssh using a login key and a domain name that is mapped to an IP address —
The main code of csinstances_create.sh is below. All it does is to run the aws_*.sh scripts that actually create instances and related resources, passing to each such script the parameter it received, the path/name of the “instancesNames.txt” file which, being the first and only parameter you specify, is stored in the script variable $1
The script csinstances_delete.sh is organised and works the same way but it runs the scripts that actually delete instances and related resources instead.
aws_loginKeyPair_create.sh "$1" || { message "$error_message"; exit 1; }
aws_instances_launch.sh "$1" || { message "$error_message"; exit 1; }
aws_elasticIPs_allocate.sh "$1" || { message "$error_message"; exit 1; }
aws_domainNames_create.sh "$1" || { message "$error_message"; exit 1; }
aws_elasticIPs_associate2ins.sh "$1" || { message "$error_message"; exit 1; }
aws_instances_configure.sh "$1" || { message "$error_message"; exit 1; }
exit 0
That all means that each aws_*.sh script is in charge of:
- a single type of AWS operation request (either create, allocate, .., deallocate, or delete)
- for one or multiple AWS resources all of the same type (either instance, login key, domain name, or IP address).
Each script will make an AWS operation request for each instance name specified in the file “instancesNames.txt”.
Such organisation means that all login keys are created first, then all instances are created, etc. — and vice versa: all instances are deleted first, then all login keys are deleted, etc.
An alternative way to organise the Scripts would be such that: each instance and its resources (login key, domain name, and IP address) are created first, then a second instance and its resources are created, and so on. But the code gets much more complicated.
Exercise: Think of that alternative organisation for the Scripts or any other organisation you would like for the Scripts.
- Is it really more complex?
- Why?
- How would
csinstances_create.shbe organised?- Do we need more or fewer scripts?
If you thought of another alternative organisation, what is the main flow in creating instances and their resources?
The aws_*.sh scripts main processing steps
Each aws_*.sh script makes an AWS operation request for each instance name specified in the file “instancesNames.txt” through these main steps:
- Determine the location of relevant “shared data” from the path of the file “instancesNames.txt (received as parameter):
- the path of the configuration files
resourcesIDs.txt,tags.txt— required by the scripts that create instances and related resources. - the path of results files (in the
outputsdirectory) that contain the AWS resources IDs — required by the scripts that delete instances and related resources, andcsinstances_stop.shandcsinstances_start.sh.
- the path of the configuration files
-
makes a list of instances names from the names specified in the file “instancesNames.txt”.
- loop through the instances names list to request, for each instance, the script-relevant AWS operation through running
awspassing required parameters — some extracted from the files in step 1.
Exercise: the code structure of
csinstances_stop.shandcsinstances_start.shis similar to that to the code structure of theaws_*.shscripts.Can you figure it out the reason for that (before looking at the code)?
The Scripts “shared data” communication
Breaking down the functionality of the Scripts as described above, or of any software system for that matter, involves designing communication between the parts. Such communication can be based either on message passing or shared data. Message passing is explicit communication between two or more specific parts. Shared data is implicit communication: all parts know where the shared data is.
The Scripts use both types of communication:
- message passing is used when passing the name of an “instancesNames.txt” file to and between the Scripts.
- shared data is used when accessing data in the files in the
inputsandoutputsdirectories of a course — which is possible through using specific names and locations for those files which, in turn, makes it possible to determine their path from the path of the “instancesNames.txt” file.
Getting the path of the inputs and outputs directories
All the aws_*.sh scripts get the path to the shared directories inputs and outputs thus:
instancesNamesFile=${1} # $1 or ${1} is the path of "instancesNames.txt" received as parameter
inputsDir=${1%/*} # inputs directory path
outputsDir=${1%/inputs*}/outputs # outputs directory path
Making the path of the outputs/”results” directory
Then, each aws_*.sh script that creates instances or related resources will use only one of the assignment statements below to make the path of the directory where it will create a file to write the results of each AWS operation request that it will issue for each instance name specified in the file “instancesNames.txt”:
outputsDirThisRun=${outputsDir}/login-keys-creation-output
outputsDirThisRun=${outputsDir}/instances-creation-output
outputsDirThisRun=${outputsDir}/ip-addresses-allocation-output
outputsDirThisRun=${outputsDir}/domain-names-creation-output
outputsDirThisRun=${outputsDir}/ip-addresses-association-output
Each aws_*.sh script that deletes instances or related resources will use only one of the assignment statements below, instead:
outputsDirThisRun=${outputsDir}/ip-addresses-deallocate-output`date '+%Y%m%d.%H%M%S'`
outputsDirThisRun=${outputsDir}/login-keys-delete-output`date '+%Y%m%d.%H%M%S'`
outputsDirThisRun=${outputsDir}/instances-delete-output`date '+%Y%m%d.%H%M%S'`
outputsDirThisRun=${outputsDir}/domain-names-delete-output`date '+%Y%m%d.%H%M%S'`
outputsDirThisRun=${outputsDir}/ip-addresses-disassociate-output`date '+%Y%m%d.%H%M%S'`
You will remember that the results of deleting instances and related resources are written to directories whose names are suffixed with the current date and time.
Getting the “shared data” in the files tags.txt and resourcesIDs.txt
The scripts aws_elasticIPs_allocate.sh, aws_instances_launch.sh and aws_loginKeyPair_create.sh load the labels in the file inputs/tags.txt into the array tags, and then copy the labels values from the tags array to variables with meaninfgul names:
tags=( `cat $inputsDir/tags.txt` )
tag_name_value=${tags[1]}
tag_group_value=${tags[3]}
tag_project_value=${tags[5]}
tag_status_value=${tags[7]}
tag_pushedby_value=${tags[9]}
tag_definedin_value=${tags[11]}
The script aws_instances_launch.sh does similarly to get the resources IDs in the file inputs/resourcesIDs.txt:
resources=( `cat $inputsDir/resourcesIDs.txt` )
resource_image_id=${resources[1]}
resource_instance_type=${resources[3]}
resource_security_group_ids=${resources[5]}
resource_subnet_id=${resources[7]}
Only the aws_instances_launch.sh uses the resources IDs.
The aws_*.sh scripts that delete instances or related resources don’t need nor use the “shared data” in the files tags.txt and resourcesIDs.txt.
The Scripts loop through instances names
Once an aws_*.sh script sets access to “shared data” as described above, the script goes through the loop where, for each instance name in the “instancesNames.txt” file, the script invokes the AWS operation request it is in charge of.
The loop of the script aws_instances_launch.sh (which creates one or multiple instances) is shown below. We have added the line numbers on the left for convenience but they don’t correspond to the actual line numbers in the script. Also, we have ommitted the code for Results Handling after the invokation of the AWS operation request with aws — such Results Handling is similar in all the aws_*.sh scripts.
01 instancesNames=( `cat $instancesNamesFile` )
02 for instance in ${instancesNames[@]}
03 do
04 logkeyend=${instance%-src*}
05 aws ec2 run-instances --image-id $resource_image_id --instance-type $resource_instance_type\
06 --key-name "login-key-${logkeyend}" \
07 --security-group-ids $resource_security_group_ids \
08 --subnet-id $resource_subnet_id --tag-specifications \
09 "ResourceType=instance, Tags=[{Key=Name, Value=$instance}, \
10 {Key=name, Value=${instance,,}}, \
11 {Key=group, Value=$tag_group_value}, \
12 {Key=project, Value=$tag_project_value}, \
13 {Key=status, Value=$tag_status_value}, \
14 {Key=pushed_by, Value=$tag_pushedby_value}, \
15 {Key=defined_in, Value=$tag_definedin_value}, \
16 ]" > $outputsDirThisRun/$instance.txt 2>&1
17 if [ $? -eq 0 ]; then
18 ### aws Results Handling
19 fi
20 done
Line 01: the variable instancesNames is initialised as list of the instances names in the file “instancesNames.txt” file (variable $instancesNamesFile).
Line 02: the loop starts, using the variable instance to store the instance name in turn.
Line 04: logkeyend=${instance%-src*} gets the end, the suffix, of the login key name to pass as parameter to aws (line 06). Each login key name is created with the fixed prefix login-key- concatenated to the instance name (in the instance variable) without the instance name suffix that identifies the source (%-src*) AMI template (discussed in episode 3).
Lines 05-16 is a single command — the character \, at the end of lines 05-12, tells Bash to carry on reading input before running the command. The command runs the AWS CLI program aws requesting to launch and instance, passing various parameters including: --image-id (AMI id), .. and the tag values (previously loaded from the file inputs/tags.txt). The parameters to aws are discussed below.
Line 16: the results of invoking aws are stored in the file whose name is specified by the value in the variables $outputsDirThisRun/$instance.txt which were previously defined before and within the loop, respectively. Both results (1) and any errors (2), if any, are written to that file (2>&1).
The loops in the other scripts
The loop in each of all other aws_*.sh scripts is similar to the loop shown above in that:
- the
instanceloop variable is used to create the name of other files to access therein data that is relevant to the function of the script. Recall that:
“Each instance name is the key to access each instance results files in theoutputsdirectory”. awsis run to make the corresponding AWS operation request.- results and errors of invoking
awsare saved to a file in theoutputs/script-results/ directory.
The loop in the scripts below are somewhat different to all others:
aws_domainNames_create.sh:
Before invokingawsto create a domain name (for theinstancebeing processed in the loop),aws_domainNames_create.shcreates a .json file with the details of the domain name to be created, and then invokesawspassing the path of that file as parameter, among other parameters.aws_loginKeyPair_create.sh:
After invokingawsto create a login key (for theinstancebeing processed in the loop), if the invocation was Successful,aws_loginKeyPair_create.shunpacks the login key from the results file (of invokingaws) into a .pem file. Such results are returned in .json format, which includes a key-value pair for each item of information returned, for example: “KeyName”: “login-key-instance01”; “KeyPairId”: “key-0f2702d75934347e4”; “KeyMaterial”: “ the login key itself “, among other items of information. The value of “KeyMaterial” is extracted from the resuts file, and somewhat processed before writing it onto a .pem file. The processing is required for the login keys to work in MacOS machines.
2. The AWS CLI Command Reference
The code box below shows some of the aws (AWS CLI) commands used by the Scripts. For each command, only the first three parameters passed to aws by the Scripts are shown (the actual commands pass quite a few more parameters).
aws ec2 create-key-pair --key-name ..
aws ec2 delete-key-pair --key-name ..
aws ec2 run-instances --image-id ..
aws ec2 terminate-instances --instance-ids ..
aws ec2 allocate-address --domain ..
aws ec2 release-address --allocation-id ..
aws route53 change-resource-record-sets --hosted-zone-id ..
aws ec2 describe-volumes --filters ..
The first parameter identifies the target main AWS service: ec2 and route53 (in the code box). The service ec2 stands for Elastic Compute Cloud which comprises quite a few sub-services or resources such as: login keys, AMI, IP addreses, volumes, snapshots, etc. The service route53 is the one that deals with domain names.
The second parameter (create-key-pair, .., or describe-volumes), is the command/operation we want the AWS service to perform. Each of the commands above has the form verb-noun, or action-onWhat, thus identifying the type of EC2 resource on which the command will be applied.
The third parameter, (--key-name, .., or --filters), and the following parameters are the parameters to the command (the second parameter of aws), identifying the target specific AWS resource to be affected and how it will be affected by the command requested.
The AWS CLI (aws) is extremely powerful and flexible. The Scripts only use only a minor part of it. The AWS CLI enables you to access and modify any AWS service and any type of resource within each service. There are over 100 AWS services, of which EC2 is one of them. EC2 has over 200 command-resource operations.
If you plan to improve the Scripts and this involves changing the aws commands in the Scripts, you need to consult the AWS CLI Command Reference, version 2
(https://awscli.amazonaws.com/v2/documentation/api/latest/reference/index.html) — the landing page is shown below.
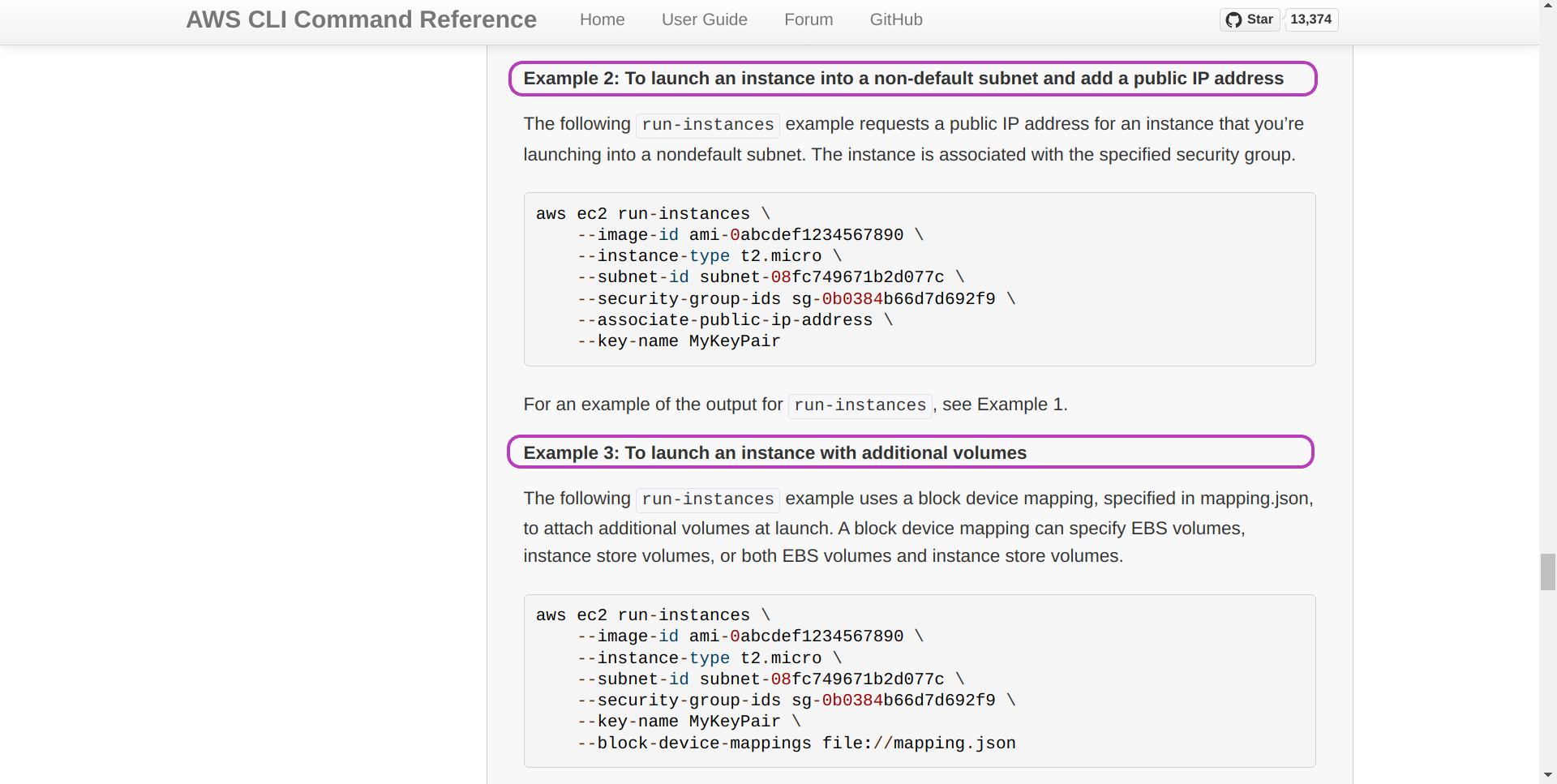
Overall, in trying a new aws command you should aim to have a simple version of the new command running as soon as possible and then tune it gradually. For this purpose, look at the relevant examples in the AWS CLI Command Reference. The screenshots below show you how to get to the Examples of the aws ec2 run-instances command that creates (runs and launches) instances. Our Script aws_instances_launch.sh uses a version of those examples.
On the “AWS CLI Command Reference” page, click on Available Services and scroll down until you find ec2 and click on it.
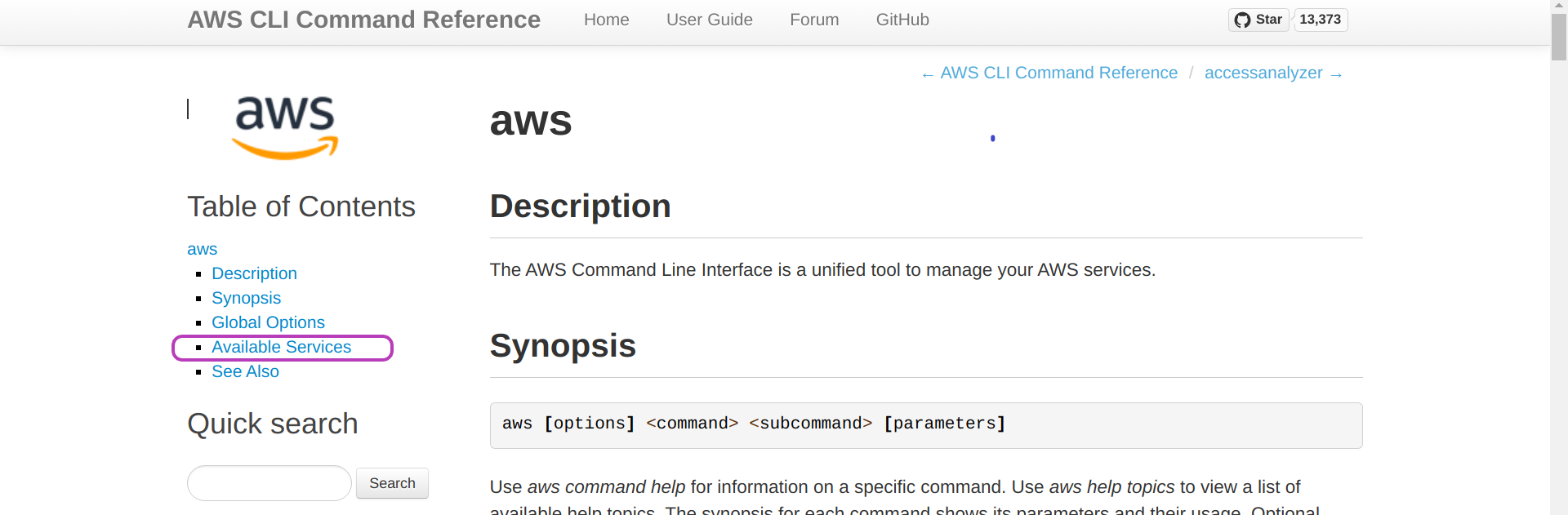
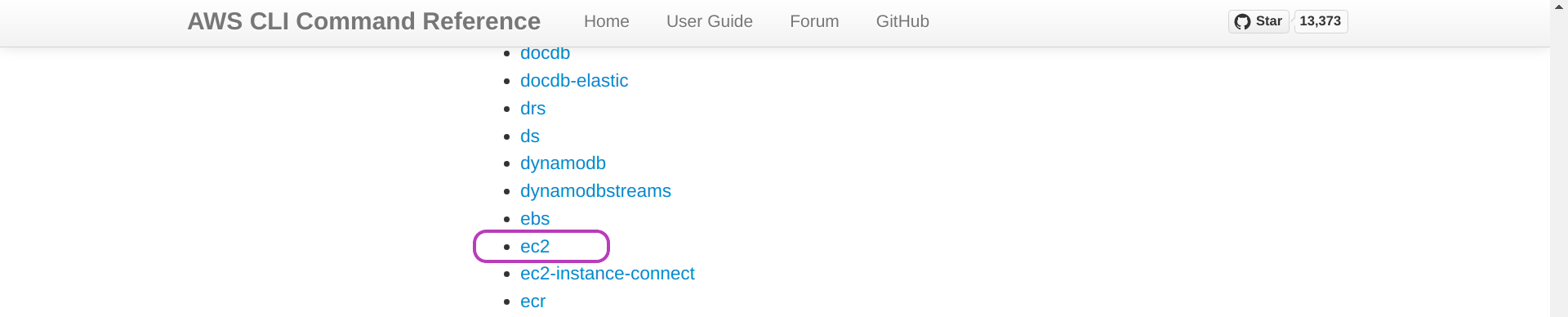
The page “ec2” will be presented. Click on Available Commands and scroll down until you find run-instances and click on it.
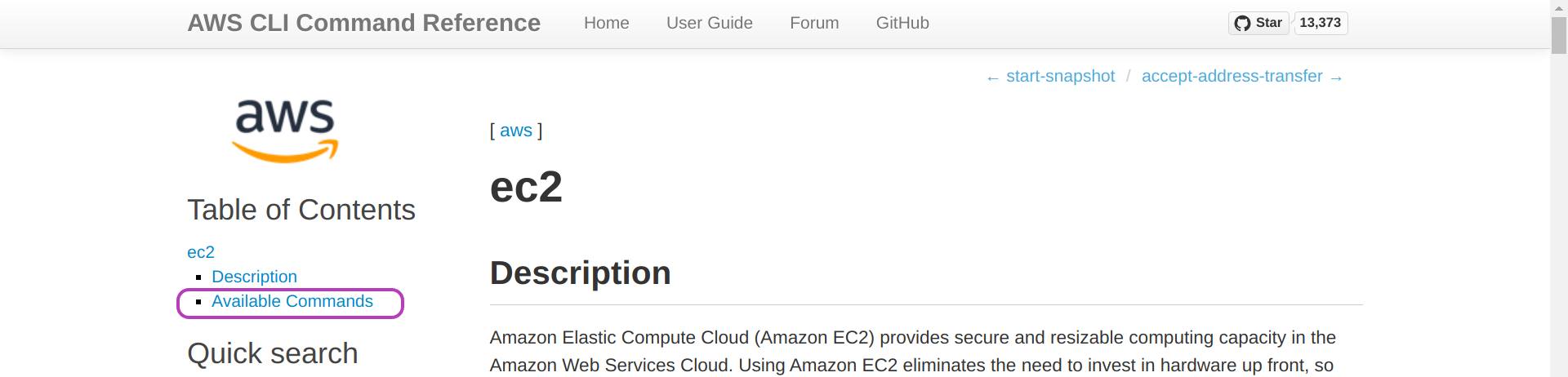

The page “run-instances” will be presented. Click on Examples.
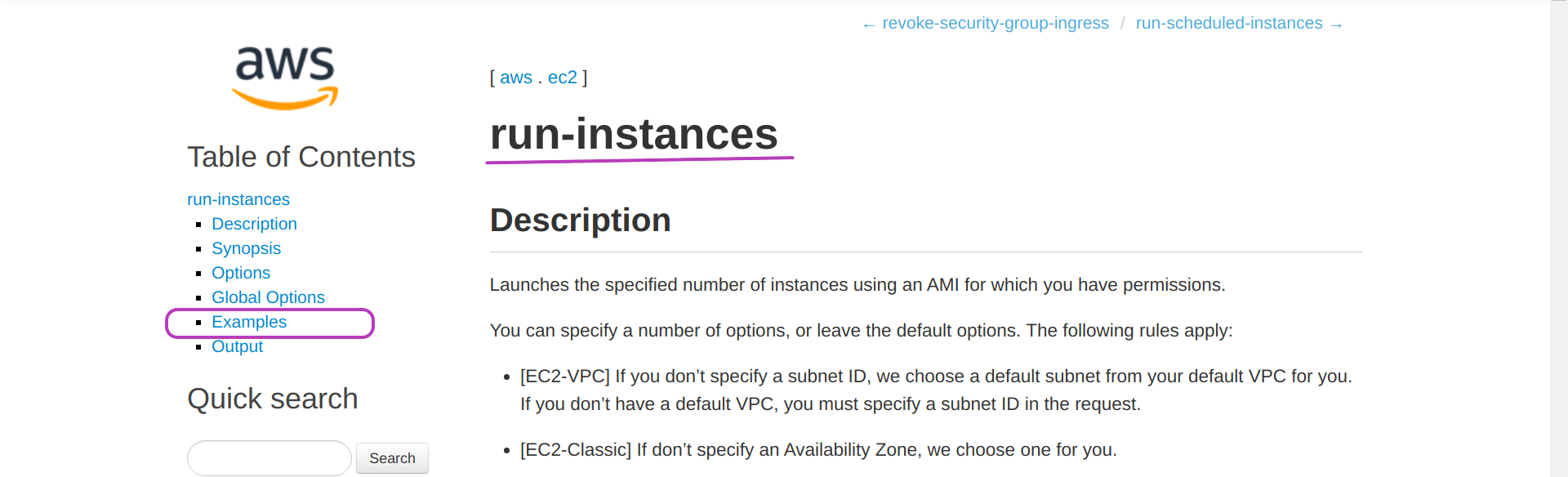
The page below will be presented. You can see the resemblance between the code in the examples below and the code in our Script aws_instances_launch.sh. The main difference being our use of shell variables to tune the aws command within the loop according to each instance name, etc.
We developed all the Scripts starting with the relevant examples in the AWS CLI Command Reference.
3. Improving the Scripts
The Scripts provide enough functionality to manage well one or multiple AWS instances in the context of hands-on training and similar contexts, wherein each instance is to be used by a single person for a period of time. Other contexts will most likely need modifying the scripts and, of course, the scripts can be improved somehow. This is a list of improvements that we have identified:
-
Handling comments in configuration files:
resourcesIDs.txt,tags.txtand “instancesNames.txt” files. This will make those files more readable. -
Code naming conventions and comments in the Scripts can be improved.
-
Checking some resouces limits (quotas) of the target AWS account. For example, the Scripts use elastic IP addresses that don’t change on rebooting instances. The default number of elastic IPs for each AWS account is 5, and can be increased in the AWS Console. However, the Scripts will fail if the number of available IP addresses is exceeded when running the Scripts: the Scripts will fail in creating the IP addresses but would have succeded in creating the login keys and the intances. Hence, after increasing that number in the AWS Console, the Scripts
aws_elasticIPs_allocate.sh,aws_domainNames_create.sh,aws_elasticIPs_associate2instance.sh, andaws_instances_configure.shwould have to be run “manually”. -
Managing dynamic IP addresses (that change on rebooting instances), as opposed to elastic IP addresses, should perhaps be considered in order to make management more efficient and less dependant on resources limits.
-
Adding the
--dry-runoption to the Scripts would facilitate development. The AWS CLI (aws) supports a--dry-runand it would be a matter of handling that option within the Scripts.
Congratulations! You have completed the course Automated Management of AWS Instances.
Key Points
The Scripts comprise a modular organisation wherein each script is a module with a specific task that can be applied to one or multiple instances.
The Scripts communicate through shared files in the
inputsandoutputsdirectories of a “course”.The AWS CLI Command Reference was our starting point to develop the Scripts based on the code examples therein.